Another way to persist DDD Aggregates in Django
Django ORM is powerful but it has its drawbacks. When you deal with more complicated domains, you may have a temptation to use concepts from DDD methodology. Soon, you will notice that it requires a lot of boring, boilerplate code that maps your Django models into Entities/Aggregates. This may look something like that:
class CreditCardORM(models.Model):
id = models.UUIDField(
primary_key=True, default=uuid.uuid4, editable=False
)
balance_amount = models.DecimalField(
max_digits=19, decimal_places=2
)
balance_currency = models.CharField(
max_length=10
)
def to_domain(self) -> CreditCard: # returns domain model
return CreditCard(
self.id,
Money(self.balance_amount, self.balance_currency)
)
@staticmethod
def update_from_domain(credit_card: CreditCard) -> None:
CreditCardORM.objects.update_or_create(
id=credit_card.id,
defaults={
"balance_amount": credit_card.balance.amount,
"balance_currency": credit_card.balance.currency
}
)# domain model
@dataclass
class CreditCard:
id: UUID4
balance: Money
def withdraw(self, withdraw_amount: Money) -> Result:
# logic ...
This model has only 3 fields but you have to maintain all changes and do it for every new Aggregate. Is it worth it?
To make my life easier I decided to leverage pydantic — a great library, that uses type hints, to provide data validation and json serialization, that we will use.
Round 1
class CreditCard(BaseModel):
id: UUID4
balance: Money # This should live in some base class.
class Config:
orm_mode = True
# logic ...
class CreditCardRepository:
def find(self, card_id: UUID4) -> Optional[CreditCard]:
card_data = CreditCardORM.objects.filter(id=card_id).first()
(1) return CreditCard.from_orm(card_data) if card_data else None
def save(self, card: CreditCard) -> None:
(2) card_snapshot = card.dict()
card_id = card_snapshot.pop("id")
CreditCardORM.objects.update_or_create(
id=card_id,
defaults=card_snapshot
)class CreditCardORM(models.Model):
id = models.UUIDField(
primary_key=True, default=uuid.uuid4, editable=False
)
balance_amount = models.DecimalField(
max_digits=19, decimal_places=2
)
balance_currency = models.CharField(
max_length=10
)
@property
def balance(self) -> Money: (3)
return Money(
amount=self.balance_amount,
currency=self.balance_currency
)
@balance.setter (3)
def balance(self, value: Union[Money, dict]) -> None:
data = value
if isinstance(value, Money):
data = value.dict()
self.balance_amount = data.get("amount")
self.balance_currency = data.get("currency")
- Use pydantic .from_orm method to easily parse from Django model to domain model.
- Use pydantic .dict() method to parse domain model to dictionary.
- We still have to manually map value objects.
Advantages:
- Builtin JSON serialization.
- Normalized database structure.
Drawbacks:
- All fields in our model have to be json serializable. This may sometimes lead to ugly serialization code in our domain model or force to use only pydantic models.
- Domain logic is not “clean python” anymore. We have dependency to external library in our core.
- To use Value Objects like Money we have to manually implement getters and setters for the object and dict.
Round 2
To make my life even simpler I decided to use JSONField instead.
class CreditCard(BaseModel):
id: UUID4
balance: Money
def withdraw(self, withdraw_amount: Money) -> Result:
# logic ...
pass
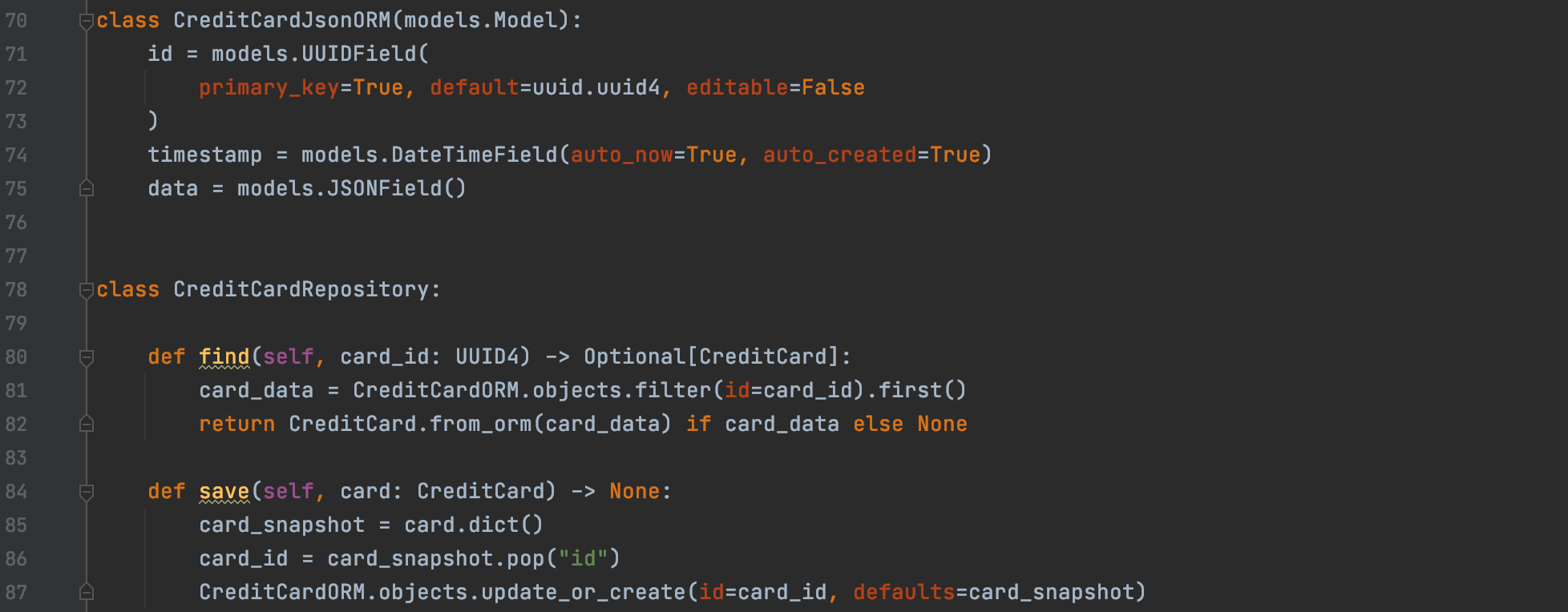
class CreditCardJsonORM(models.Model):
id = models.UUIDField(
primary_key=True, default=uuid.uuid4, editable=False
)
timestamp = models.DateTimeField(
auto_now=True, auto_created=True
)
data = models.JSONField()
class CreditCardJsonRepository:
def find(self, card_id: UUID4) -> Optional[CreditCard]:
try:
credit_card_model = CreditCardJsonORM.objects.get(
id=card_id
)
return CreditCard.parse_obj(credit_card_model.data) (1)
except CreditCardJsonORM.DoesNotExist:
return None
def save(self, card: CreditCard) -> None:
card_snapshot = json.loads(card.json()) (2)
CreditCardJsonORM.objects.update_or_create(
id=card.id, data=card_snapshot
)
- Thanks to dynamic json schema I don’t have to maintain mapping between models or even use pydantic orm_mode.
- Use pydantic .json() method to parse domain model this time.
Advantages
- Thanks to dynamic schema we can try to create one generic repository for all Aggregates.
- Will also work with noSQL document databases like Mongo.
- Value Objects parsed without any getters or setters.
Drawbacks
- Reading data from JSON fields could be harder and slower. Probably forces us to use CQRS pattern.
- Serialization still may be problematic.
That was my experimental approach to aggregates persistence. I tried it on medium project, that has MongoDB underneath, and it worked pretty well. Let me know what you think!
